مقال : برمجه الأداه الخاصه بك للبحث في جوجل وفحص الثغرات بلغه البايثون – الجزء الأول
في هذه المقاله سأقوم بالشرح ” خطوه بخطوه ” كيف تقوم ببرمجه الـGoogle Scraper الخاص بك بسهوله بلغه البايثون ومن ثم جعله Scanner أو Mass Exploiter
المتطلبات :
- بايثون أصدار 3
- مكتبه Requests
- مكتبه Beautifulsoup4
ولتثبيت المكتبات المطلوبه نقوم بالأمر الأتي :
python -m pip install requests beautifulsoup4
أولا لنفهم كيف يعمل البحث في جوجل
http://www.google.com/search
هذا الرابط يأخذ 2 باراميتر وهما q و start
الباراميتر q يحمل الكلمه التي نبحث عنها
الباراميتر start يحمل رقم صفحه البحث التي نحن بها مضروب في 10
ولذلك أذا أردت مثلا البحث عن كلمه isecur1ty فستكون هذه النتيجه
الصفحه 0 : http://www.google.com/search?q=isecur1ty&start=0 الصفحه 1 : http://www.google.com/search?q=isecur1ty&start=10 الصفحه 2 : http://www.google.com/search?q=isecur1ty&start=20 الصفحه 3 : http://www.google.com/search?q=isecur1ty&start=30 ... ....
والأن لنقوم بعمل تجربه بسيطه ونري أذا كنا سنستطيع أن نأتي بكود الصفحه الأولي في البحث
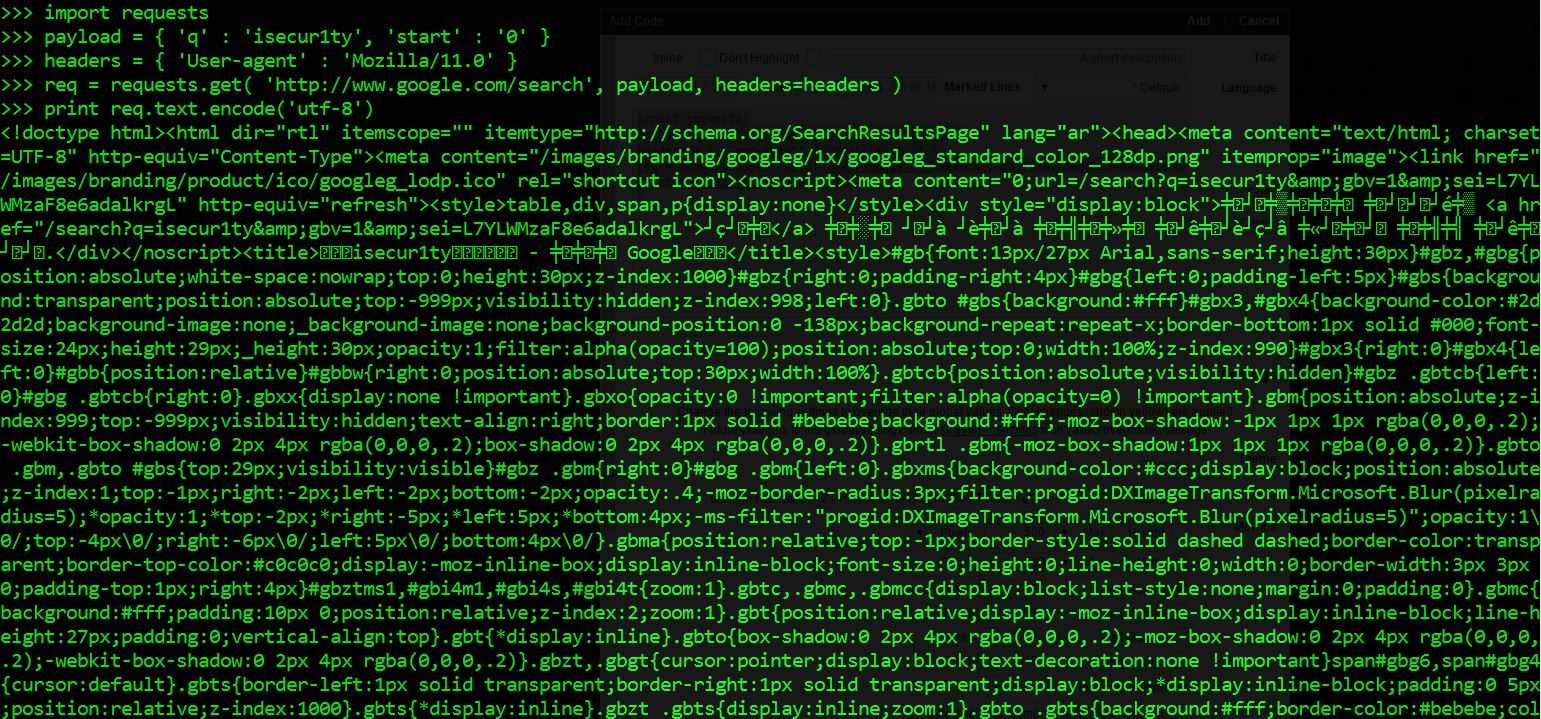
import requests
payload = { 'q' : 'isecur1ty', 'start' : '0' }
headers = { 'User-agent' : 'Mozilla/11.0' }
req = requests.get( 'http://www.google.com/search', payload, headers=headers )
print(req.text.encode('utf-8'))
فيقوم بكتابه الكود المصدري للصفحه الأولي
الأن سنستخدم مكتبه beautifulsoup4 لجلب البيانات التي نحتاجها فقط من الكود
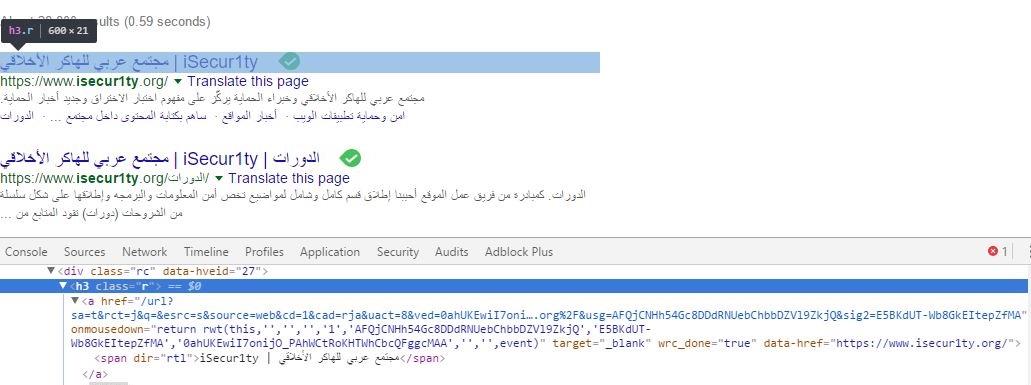
كما نري فالبيانات التي نحتاجها تكمن داخل تاج h3 بالـclass r
اذا نستنتج الأن أن كل صفحه سيكون بها 10 تاجات <“h3 class=”r> وبداخل كل تاج <a href> يحتوي علي الرابط الخاص بنتيجه البحث
اذا الأن سنستخدم مكتبه beautifulsoup4 ومكتبه re لفرز نتيجه البحث
import requests, re
from bs4 import BeautifulSoup
payload = { 'q' : 'isecur1ty', 'start' : '0' }
headers = { 'User-agent' : 'Mozilla/11.0' }
req = requests.get( 'http://www.google.com/search', payload, headers=headers )
soup = BeautifulSoup( req.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
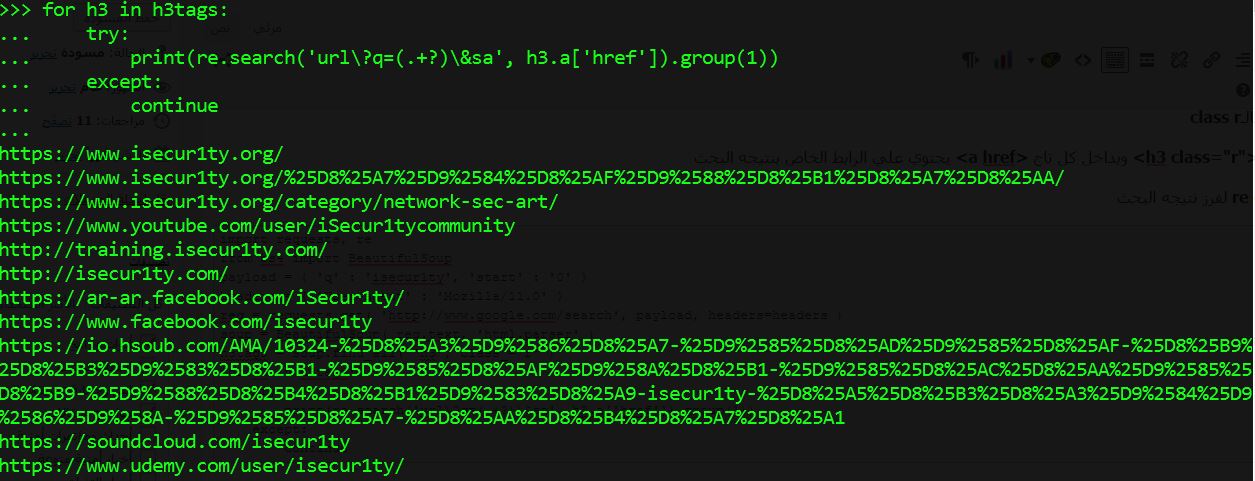
for h3 in h3tags:
try:
print(re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1))
except:
continue
فستجد روابط الصفحه الأولي في البحث
الأن لنقوم بتنظيم الكود قليلا ولذلك سأقوم بعمل داله للبحث ولجعل الأداه قابله للأستخدام من التيرمنال سأقوم بأستخدام مكتبه sys ولكن تستطيع أستخدام أي مكتبه أخري أذا أردت مثل argparse أو docopt
import requests, re, sys, time
from bs4 import BeautifulSoup
def search_for(string, start):
urls = []
payload = { 'q' : string, 'start' : start }
headers = { 'User-agent' : 'Mozilla/11.0' }
req = requests.get( 'http://www.google.com/search',payload, headers = headers )
soup = BeautifulSoup( req.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
for h3 in h3tags:
try:
urls.append( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
return urls
def printf(lista): #To print list line by line like printf in python 3
for i in lista:
print( " " + str( i ) )
usage = """ Usage:
Mass_Exploiter.py <search> <pages>
<search> String to be searched for
<pages> Number of pages to search in"""
try:
string = sys.argv[1]
page = sys.argv[2]
if string.lower() == "-h" or string.lower() == "--help":
print(usage)
exit(0)
except:
print(" * * Error * * Arguments missing")
print("\n"+usage)
exit(0)
start_time = time.time()
result = []
for p in range(0,int(page)):
result = result + search_for( string, str(page*10) )
printf( set( result ) )
print( " Number of urls : " + str( len( result ) ) )
print( " Finished in : " + str( int( time.time() - start_time ) ) + "s")
والأن نقوم بتجربته بالبحث عن كلمه facebook وعرض نتايج أول صفحه فقط
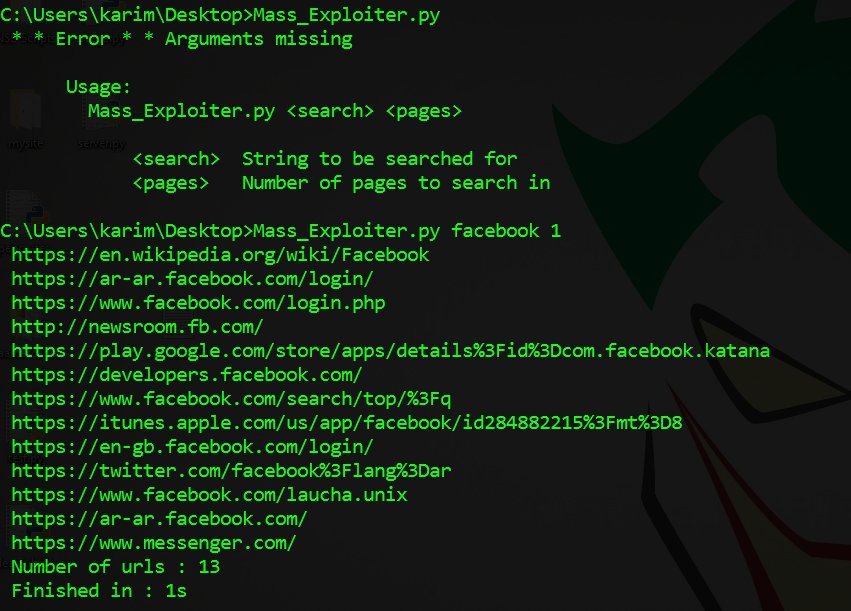
رائع الكود يعمل بسلاسه والأن لنضيف أليه السرعه ليقوم بفحص صفحات أكثر في وقت أقل وسنقوم بذلك عن طريق مكتبه Multiprocessing فيصبح الكود كالأتي
import requests, re, sys, time
from bs4 import BeautifulSoup
from functools import partial
from multiprocessing import Pool
def search_for(string, start):
urls = []
payload = { 'q' : string, 'start' : start }
headers = { 'User-agent' : 'Mozilla/11.0' }
req = requests.get( 'http://www.google.com/search',payload, headers = headers )
soup = BeautifulSoup( req.text, 'html.parser' )
h3tags = soup.find_all( 'h3', class_='r' )
for h3 in h3tags:
try:
urls.append( re.search('url\?q=(.+?)\&sa', h3.a['href']).group(1) )
except:
continue
return urls
def printf(lista): #To print list line by line like printf in python 3
for i in lista:
print( " " + str( i ) )
def main():
usage = """ Usage:
Mass_Exploiter.py <search> <pages> <processes>
<search> String to be searched for
<pages> Number of pages to search in
<processes> Number of parallel processes"""
try:
string = sys.argv[1]
page = sys.argv[2]
proc = int( sys.argv[3] )
if string.lower() == "-h" or string.lower() == "--help":
print(usage)
exit(0)
except:
print(" * * Error * * Arguments missing")
print("\n"+usage)
exit(0)
start_time = time.time()
result = []
request = partial( search_for, string )
pages = []
for p in range( 0, int(page)):
pages.append(p*10)
with Pool(proc) as p:
all = p.map(request, pages)
for p in all:
result += [ u for u in p]
printf( set( result ) )
print( " Number of urls : " + str( len( result ) ) )
print( " Finished in : " + str( int( time.time() - start_time ) ) + "s")
if __name__ == '__main__':
main()
لاحظ أنني قمت بأستخدام مكتبه functools حتي أقوم بتجزئه المهام علي كل بروسيس
والأن نقوم بأختبار السكربت بالبحث عن كلمه facebook مجددا ولكن في 20 صفحه وسأستخدم 6 بروسيس ولنري كيف أصبحت سرعه السكربت 😀
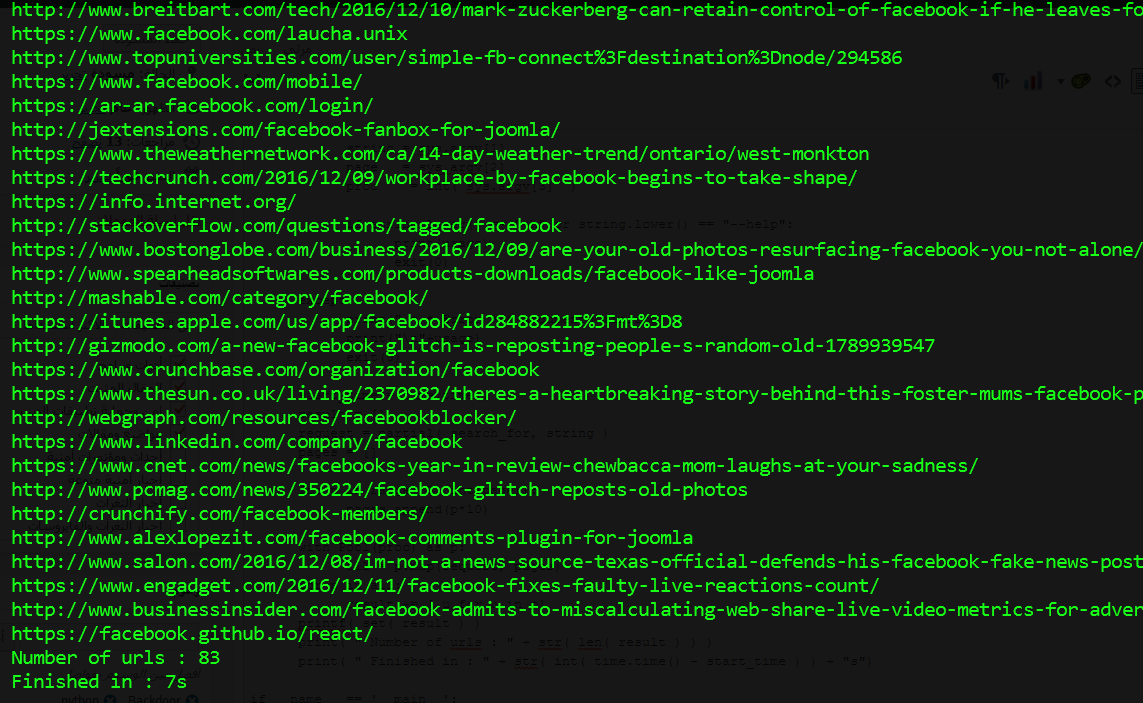
كما تري السكربت أصبح أسرع بحوالي 6 مرات عند أستخدام
تحذير :
لا تقم بأستخدام أكثر من 8 بروسيس حيث أن جوجل سيقوم بعمل حذر لجهازك أو بأظهار كابتشا بدل صفحه البحث , ولذلك يفضل أن لا يظل عدد البروسيس أقل من 8 .
وكان هذا الجزء الأول من طريقه عمل الأداه الخاصه بك للبحث في جوجل وفحص الثغرات بلغه البايثون وفي المقاله القادمه سأشرح كيف تطور هذه الأداه وتجعلها تفحص المواقع من الثغرات مثل sqli
المصدر الرئيسي للمقاله
جزاك الله خير ان شاء الله
بانتظار الجزء الثاني …
هذي الشروحات البطله
شرح تشكر عليه 100%
اتمنى بالمقالات القادمة يكون في تعليقات بالكود تشرح كل سطر